Kiểm thử các giải pháp
Các giải pháp / kỹ thuật scaling
ℹ️ Information: Dịch vụ Auto Scaling Group cung cấp nhiều giải pháp scaling khác nhau, tùy thuộc vào nhu cầu và mức độ sử dụng hệ thống. Chúng ta cần tính toán, ước lượng, quan sát và lập kế hoạch sử dụng từng loại hoặc kết hợp các loại với nhau để tăng độ linh hoạt của hệ thống.
Trong phần này, chúng ta sẽ thử nghiệm từng giải pháp, nhưng trước tiên hãy tìm hiểu sơ lược về các giải pháp scaling này.
Manual scaling
ℹ️ Information: Manual Scaling là việc chúng ta thực hiện mở rộng hay thu hẹp các target trong một Target Group bằng cách điều chỉnh thông số Desired capacity trong Auto Scaling Group. Trong một số tình huống đơn lẻ, cần xử lý nhanh, chúng ta cần thực hiện việc thêm và bớt các targets thủ công.
Scheduled scaling
ℹ️ Information: Khi chúng ta nắm rõ được lưu lượng mạng vào và ra của hệ thống hoặc thời điểm mà các target hoạt động ở công suất gần như cao nhất, và hoạt động này diễn ra liên tục và mang tính dài hạn (có thể là hàng năm), chúng ta có thể đặt lịch (và hẹn giờ) để Auto Scaling Group thực hiện việc mở rộng và thu gọn các targets.
Dynamic scaling
ℹ️ Information: Nếu lưu lượng mạng đi vào hệ thống không diễn ra theo một trật tự nào và khó đoán, chúng ta có thể dùng giải pháp tự động scaling của ASG. Khi đó, ASG sẽ dựa vào cấu hình Dynamic scaling policy để triển khai việc mở rộng và thu gọn các targets cho phù hợp hơn với hệ thống.
Predictive scaling
ℹ️ Information: Predictive scaling là kỹ thuật giúp ASG dự đoán lưu lượng mạng trong vòng 3 hoặc nhiều ngày tới. Với những hệ thống khó đoán, chúng ta có thể kết hợp giải pháp này với Dynamic scaling để tăng tính linh hoạt cho hệ thống. Giải pháp này sẽ biểu diễn các thông số tùy vào cấu hình, nhưng ý tưởng chung vẫn là dự đoán trước các lưu lượng và mức sử dụng trong hệ thống.
Vì khi thực hiện phần này chúng ta không có dữ liệu ở phần trước, nên đó là lý do mà chúng ta cần phải chuẩn bị và chạy dữ liệu mẫu ở phần 2.6 - Prepare metrics for predictive scaling trước đó.
Cài đặt chương trình kiểm thử
ℹ️ Information: Trước khi đi vào phần này, chúng ta cần tải một chương trình kiểm thử để có thể giả lập hệ thống đang chịu tải ở lưu lượng cao. Đầu tiên, vào đường dẫn này để tải chương trình kiểm thử về: https://www.paessler.com/tools/webstress
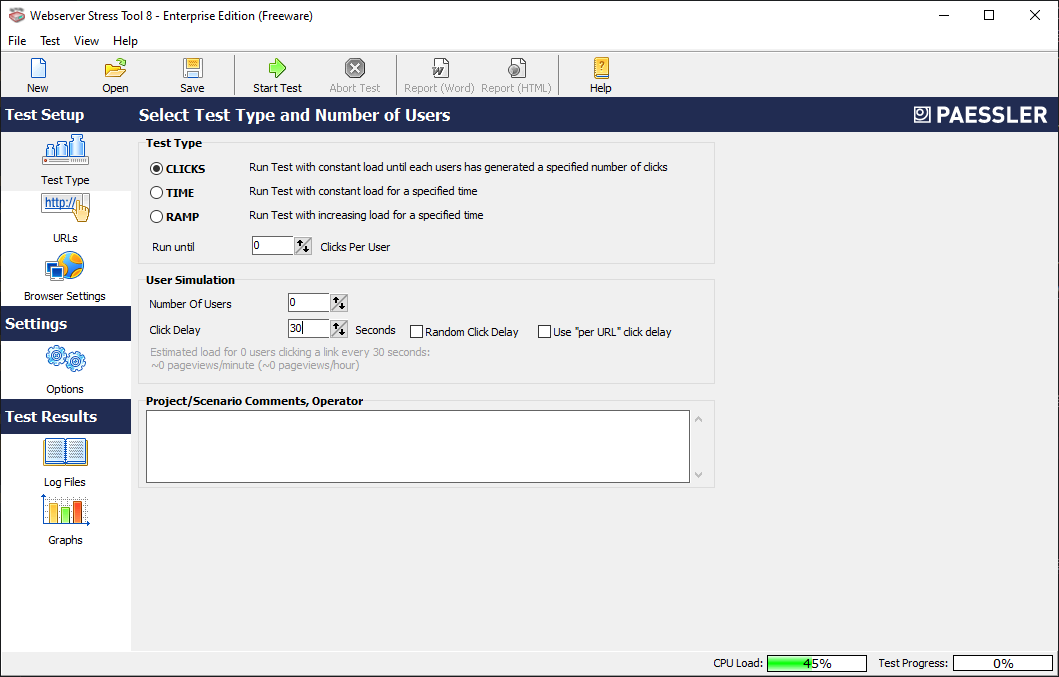
Chúng ta sẽ tải về file Rar, trích xuất file cài đặt ở bên trong và cài đặt chương trình. Sau khi cài đặt xong, chúng ta vào chương trình và sẽ thấy giao diện như sau:
Nội dung
- Kiểm thử giải pháp manual scaling
- Kiểm thử giải pháp scheduled scaling
- Kiểm thử giải pháp dynamic scaling
- Kiểm thử giải pháp predictive scaling
Thời gian để làm phần này khá lâu và cần phải quan sát kỹ lưỡng (bạn có thể test trong quá trình chạy kiểm thử), nên bạn phải kiên nhẫn và kỹ lưỡng để quan sát kết quả.
Lưu ý khi thực hiện kiểm thử
⚠️ Warning: Khi thực hiện các bài kiểm thử scaling, cần lưu ý một số điểm sau:
-
Chi phí: Mỗi khi ASG tạo thêm instance, bạn sẽ phải trả phí cho các instance đó. Hãy đảm bảo thiết lập giới hạn số lượng instance tối đa (Max capacity) phù hợp với ngân sách của bạn.
-
Thời gian chờ: Các metrics trong CloudWatch thường có độ trễ khoảng 1-5 phút. Đồng thời, việc khởi tạo instance mới cũng cần thời gian. Vì vậy, hãy kiên nhẫn khi theo dõi kết quả kiểm thử.
-
Dọn dẹp tài nguyên: Sau khi hoàn thành kiểm thử, hãy đảm bảo xóa các chính sách scaling không cần thiết và điều chỉnh lại Desired capacity về mức phù hợp để tránh phát sinh chi phí không mong muốn.
-
Kết hợp các giải pháp: Trong môi trường thực tế, việc kết hợp nhiều loại scaling (như Dynamic với Predictive) thường mang lại hiệu quả tốt hơn so với chỉ sử dụng một loại.
💡 Pro Tip: Nên thiết lập các cảnh báo (CloudWatch Alarms) để được thông báo khi số lượng instance vượt quá ngưỡng nhất định, giúp kiểm soát chi phí tốt hơn trong quá trình kiểm thử.
Các metrics quan trọng cần theo dõi
Khi thực hiện kiểm thử các giải pháp scaling, bạn nên theo dõi các metrics sau:
- CPU Utilization: Phần trăm sử dụng CPU của các instance
- Network In/Out: Lưu lượng mạng vào/ra của các instance
- Request Count Per Target: Số lượng request mà mỗi target nhận được
- Target Response Time: Thời gian phản hồi của các target
- Healthy Host Count: Số lượng host đang hoạt động bình thường
Việc theo dõi các metrics này sẽ giúp bạn đánh giá hiệu quả của các giải pháp scaling và điều chỉnh cấu hình cho phù hợp với nhu cầu thực tế của ứng dụng.