Kiểm tra kết quả
Kiểm tra kết quả triển khai
ℹ️ Information: Sau khi hoàn tất việc triển khai Load Balancer, chúng ta cần xác minh rằng hệ thống đang hoạt động đúng như mong đợi. Việc kiểm tra này giúp đảm bảo rằng lưu lượng truy cập được phân phối chính xác đến ứng dụng của chúng ta.
Để truy cập ứng dụng, hãy sử dụng DNS name của Load Balancer và dán vào trình duyệt web:
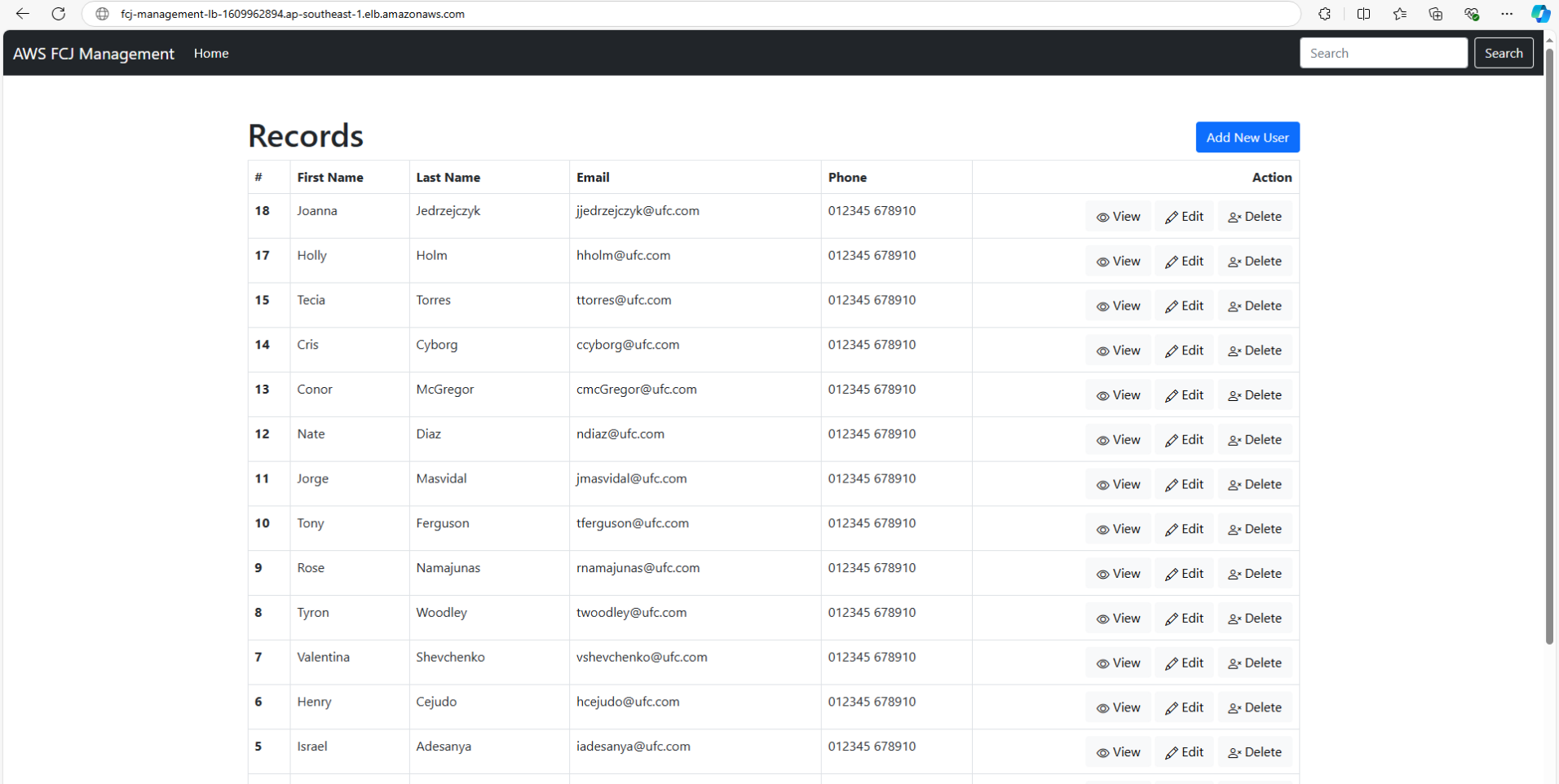
Kết quả hiển thị trang web ứng dụng quản lý của chúng ta:
💡 Pro Tip: Luôn sử dụng DNS name của Load Balancer thay vì địa chỉ IP trực tiếp của EC2 instance. Điều này đảm bảo ứng dụng của bạn vẫn hoạt động ngay cả khi các instance cơ bản được thay thế hoặc mở rộng.
Kiểm tra tính ổn định của hệ thống
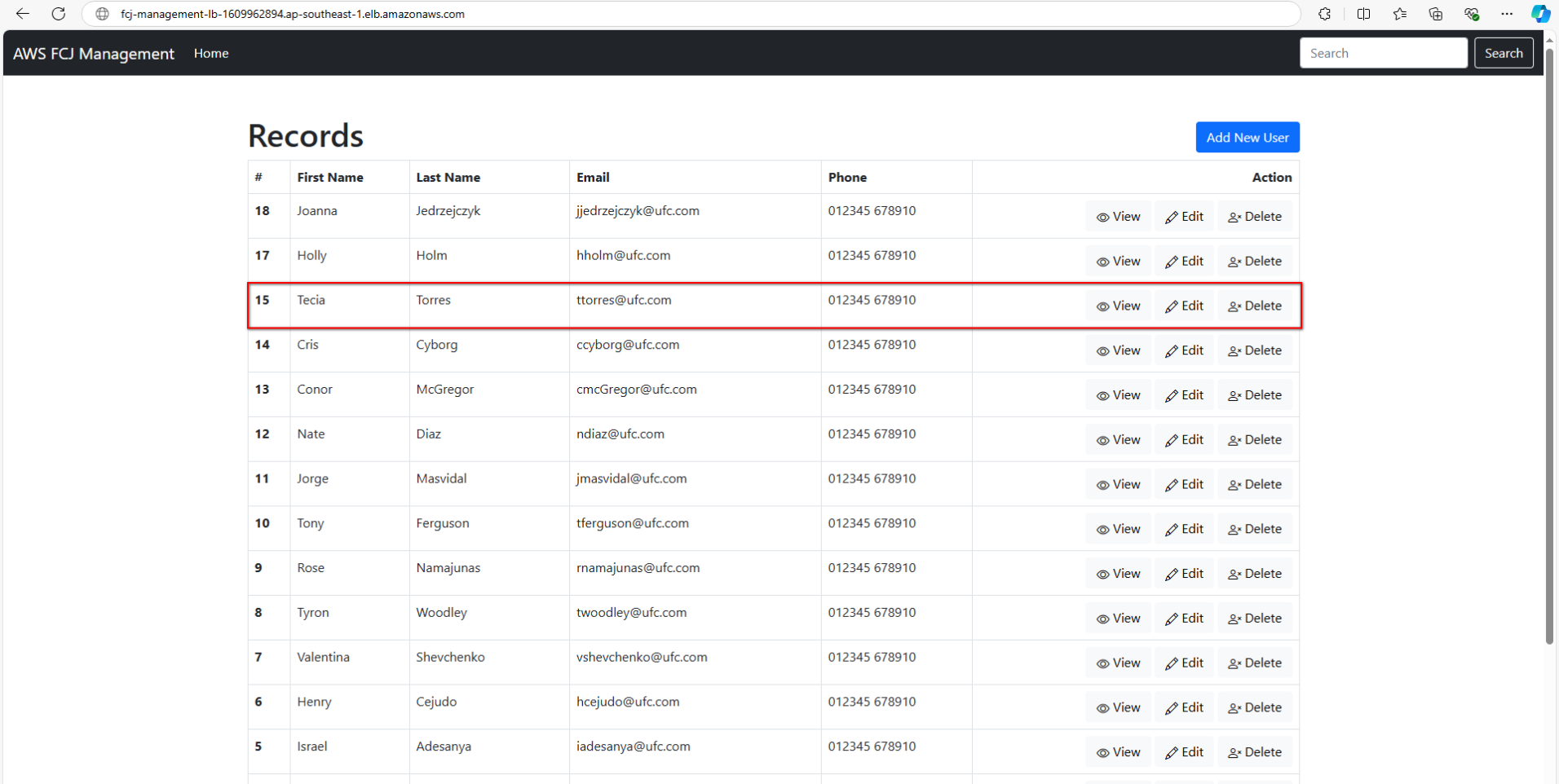
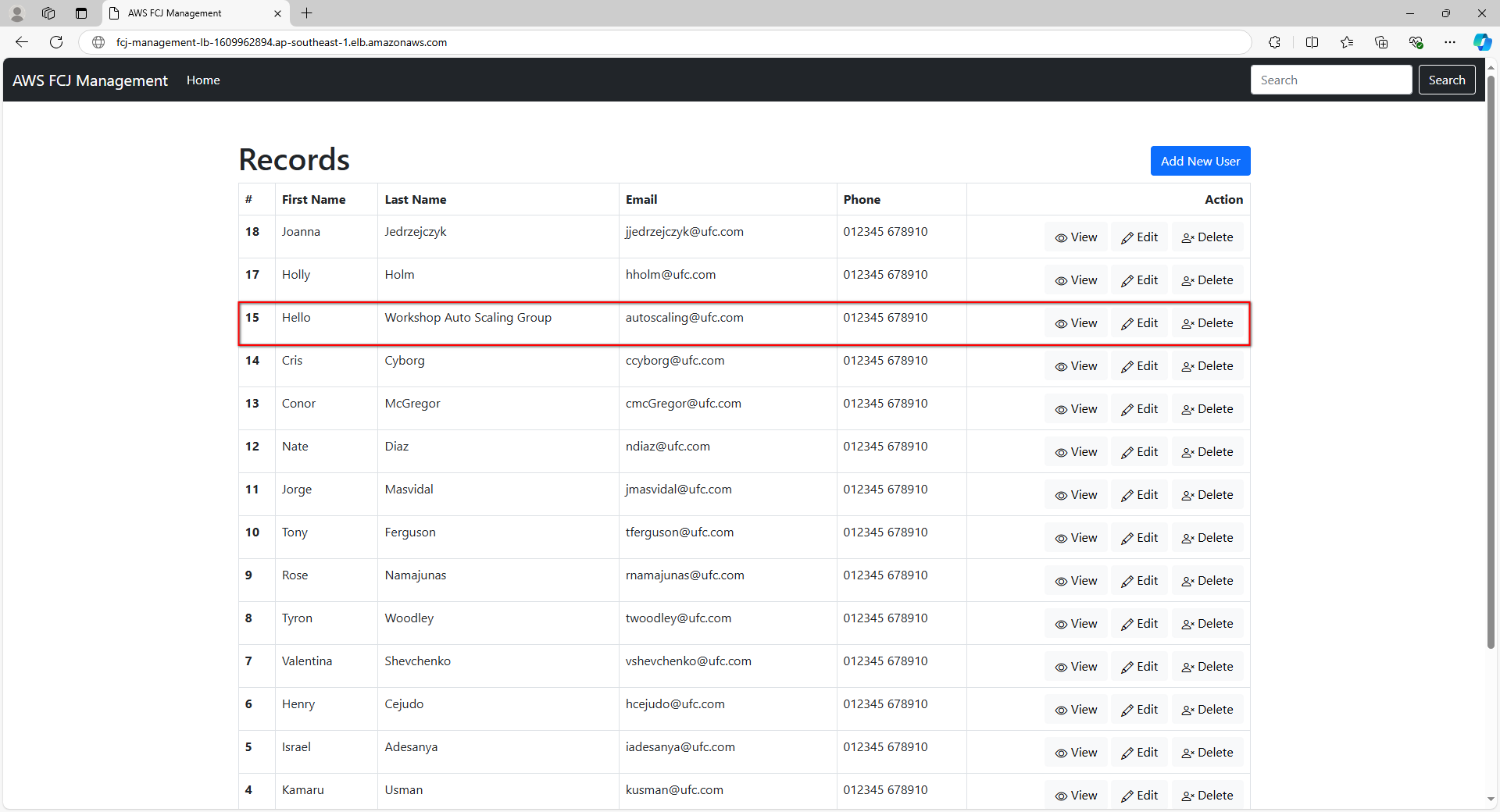
Để xác minh rằng hệ thống hoạt động ổn định, chúng ta sẽ thực hiện một số thao tác cơ bản. Đầu tiên, hãy thử thay đổi thông tin của một record trong ứng dụng:
Sau khi nhập thông tin, nhấn Submit và quan sát thông báo xác nhận:
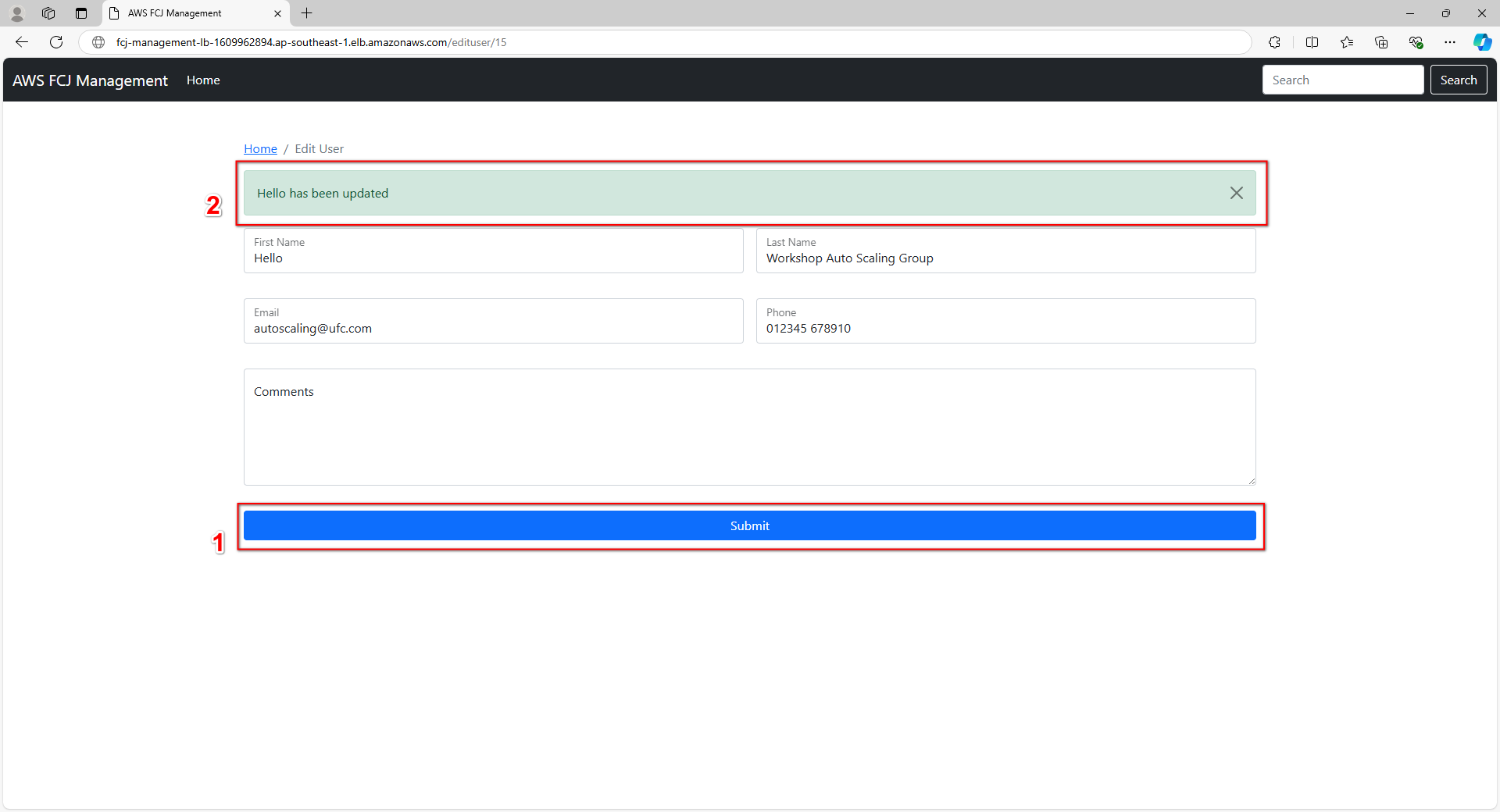
Quay lại trang chủ, chúng ta có thể thấy thông tin đã được cập nhật thành công:
⚠️ Warning: Trong các bước kiểm thử tiếp theo, chúng ta sẽ tập trung vào việc phân tích các metrics từ CloudWatch. Tuy nhiên, bạn nên kết hợp việc theo dõi metrics với việc kiểm tra trải nghiệm người dùng thực tế để đánh giá toàn diện hiệu suất của hệ thống.
🔒 Security Note: Khi kiểm tra ứng dụng qua Load Balancer, hãy đảm bảo rằng bạn đang sử dụng kết nối an toàn (HTTPS) nếu ứng dụng của bạn xử lý dữ liệu nhạy cảm. Trong môi trường sản xuất, việc cấu hình SSL/TLS cho Load Balancer là một thực hành bảo mật quan trọng.
Kiểm tra khả năng chịu tải của hệ thống
ℹ️ Information: Một trong những lợi ích chính của việc sử dụng Load Balancer là khả năng phân phối tải đồng đều giữa các EC2 instance. Để kiểm tra khả năng này, chúng ta có thể theo dõi các metrics trên CloudWatch.
Truy cập vào dịch vụ CloudWatch từ AWS Management Console:
Trong CloudWatch, chúng ta có thể xem các metrics của Load Balancer như RequestCount, TargetResponseTime, và HTTPCode:
💡 Pro Tip: Thiết lập CloudWatch Dashboards để theo dõi các metrics quan trọng của hệ thống trong một giao diện tập trung, giúp bạn nhanh chóng phát hiện các vấn đề tiềm ẩn.
Kiểm tra khả năng tự phục hồi
Một tính năng quan trọng của kiến trúc sử dụng Load Balancer và Auto Scaling Group là khả năng tự phục hồi khi có instance gặp sự cố. Để kiểm tra tính năng này:
- Truy cập vào EC2 Management Console
- Chọn một trong các instance đang chạy trong Auto Scaling Group
- Thực hiện thao tác terminate instance
Sau khi terminate instance, Auto Scaling Group sẽ tự động phát hiện và khởi tạo một instance mới để thay thế:
⚠️ Warning: Trong quá trình Auto Scaling Group tạo instance mới, có thể có một khoảng thời gian ngắn khi hệ thống hoạt động với công suất giảm. Tuy nhiên, Load Balancer sẽ tiếp tục định tuyến lưu lượng đến các instance khỏe mạnh còn lại.
Kiểm tra khả năng mở rộng tự động
Auto Scaling Group cho phép hệ thống tự động mở rộng khi tải tăng cao. Để kiểm tra tính năng này, chúng ta có thể tạo tải nhân tạo lên hệ thống và quan sát phản ứng:
- Sử dụng công cụ tạo tải như Apache JMeter hoặc AWS Load Testing
- Theo dõi các metrics như CPU Utilization trên CloudWatch
- Quan sát Auto Scaling Group tự động tăng số lượng instance khi tải vượt ngưỡng
💡 Pro Tip: Khi thiết kế các bài kiểm tra tải, hãy mô phỏng các mẫu lưu lượng thực tế mà ứng dụng của bạn dự kiến sẽ gặp phải. Điều này giúp bạn đánh giá chính xác hơn hiệu suất của hệ thống trong điều kiện thực tế.
Kiểm tra khả năng chịu lỗi của Availability Zone
Một lợi ích lớn của việc triển khai ứng dụng trên nhiều Availability Zone là khả năng chịu lỗi khi một AZ gặp sự cố. Để kiểm tra tính năng này:
- Truy cập vào VPC Management Console
- Chọn một subnet trong một AZ cụ thể mà ứng dụng đang chạy
- Tạm thời vô hiệu hóa lưu lượng đến subnet đó bằng cách điều chỉnh Network ACLs
Quan sát Load Balancer tự động định tuyến lưu lượng đến các instance trong các AZ còn lại:
🔒 Security Note: Khi thực hiện các bài kiểm tra chịu lỗi, hãy đảm bảo rằng bạn có kế hoạch khôi phục rõ ràng để nhanh chóng khôi phục hệ thống về trạng thái bình thường sau khi hoàn thành kiểm tra.
Kết luận
Qua các bài kiểm tra, chúng ta đã xác nhận rằng hệ thống triển khai với Load Balancer và Auto Scaling Group hoạt động hiệu quả, đảm bảo tính sẵn sàng cao và khả năng mở rộng linh hoạt cho ứng dụng FCJ-Management.
Kiến trúc này cung cấp nhiều lợi ích quan trọng:
- Tính sẵn sàng cao: Ứng dụng vẫn hoạt động ngay cả khi một số instance hoặc một AZ gặp sự cố.
- Khả năng mở rộng tự động: Hệ thống tự động điều chỉnh số lượng instance dựa trên nhu cầu thực tế.
- Cân bằng tải hiệu quả: Load Balancer đảm bảo lưu lượng được phân phối đồng đều giữa các instance.
- Tự phục hồi: Khi một instance gặp sự cố, hệ thống tự động thay thế nó với một instance mới.
💡 Pro Tip: Để tối ưu hóa hơn nữa hệ thống trong môi trường sản xuất, hãy xem xét việc triển khai các giải pháp giám sát và cảnh báo toàn diện, cũng như thiết lập các kế hoạch khôi phục sau thảm họa (DR) chi tiết.